DRAG DROP (Drag and Drop is not supported)
You manage a Power BI dataset that queries a fact table named SalesDetails. SalesDetails contains three date columns named OrderDate, CreatedOnDate, and ModifiedDate.
You need to implement an incremental refresh of SalesDetails. The solution must ensure that OrderDate starts on or after the beginning of the prior year.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.
Select and Place:
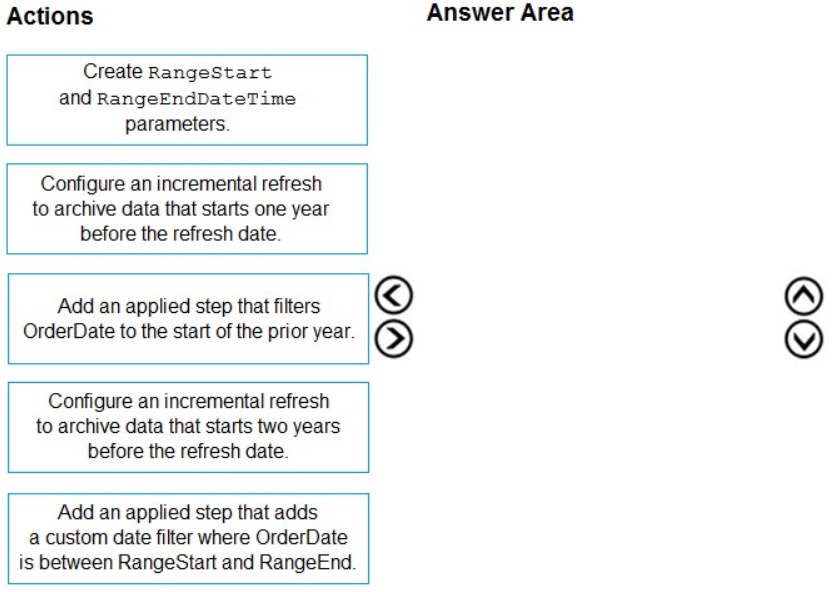
- See Explanation section for answer.
Answer(s): A
Explanation:
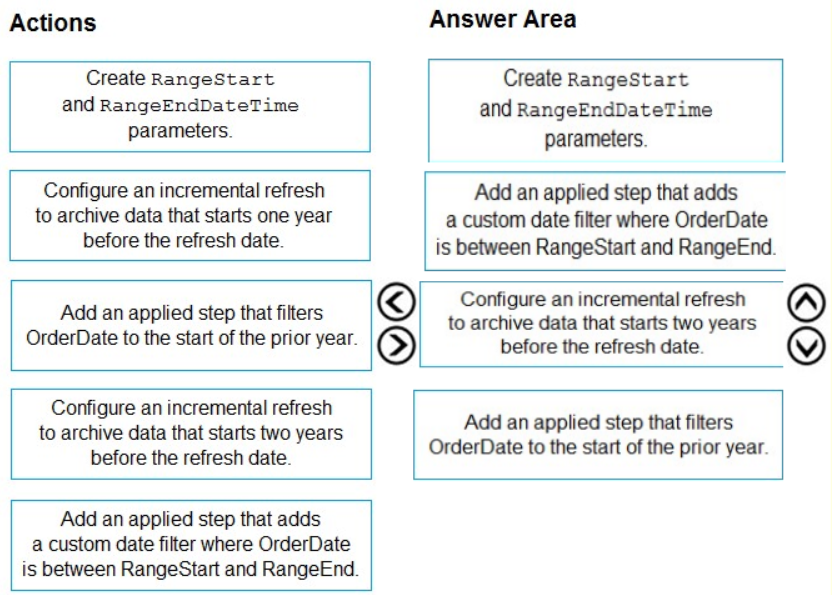
Step 1: Create RangeStart and RangeEndDateTime parameters.
When configuring incremental refresh in Power BI Desktop, you first create two Power Query date/time parameters with the reserved, case-sensitive names RangeStart and RangeEnd. These parameters, defined in the Manage Parameters dialog in Power Query Editor are initially used to filter the data loaded into the Power BI Desktop model table to include only those rows with a date/time within that period.
Step 2: Add an applied step that adds a custom date filter OrderDate is Between RangeStart and RangeEnd.
With RangeStart and RangeEnd parameters defined, you then apply custom Date filters on your table's date column. The filters you apply select a subset of data that will be loaded into the model when you click Apply.
Step 3: Configure an incremental refresh to archive data that starts two years before the refresh date.
After filters have been applied and a subset of data has been loaded into the model, you then define an incremental refresh policy for the table. After the model is published to the service, the policy is used by the service to create and manage table partitions and perform refresh operations. To define the policy, you will use the Incremental refresh and real-time data dialog box to specify both required settings and optional settings.
Step 4: Add an applied step that filters OrderDate to the start of the prior year.
Reference:
https://docs.microsoft.com/en-us/power-bi/connect-data/incremental-refresh-overview